Open Science Archive
An open-source, domain-agnostic scientific data archive.
Scroll
An open-source, domain-agnostic scientific data archive.
OSA is open-source software for running a scientific archive: validated records, version history, and query APIs. Designed for long-lived, public-facing, AI-ready data.
Deploy it on your infrastructure, then add the domain logic that makes it valuable.

Every serious archive needs the same core workflow. OSA provides it as a first-class system:
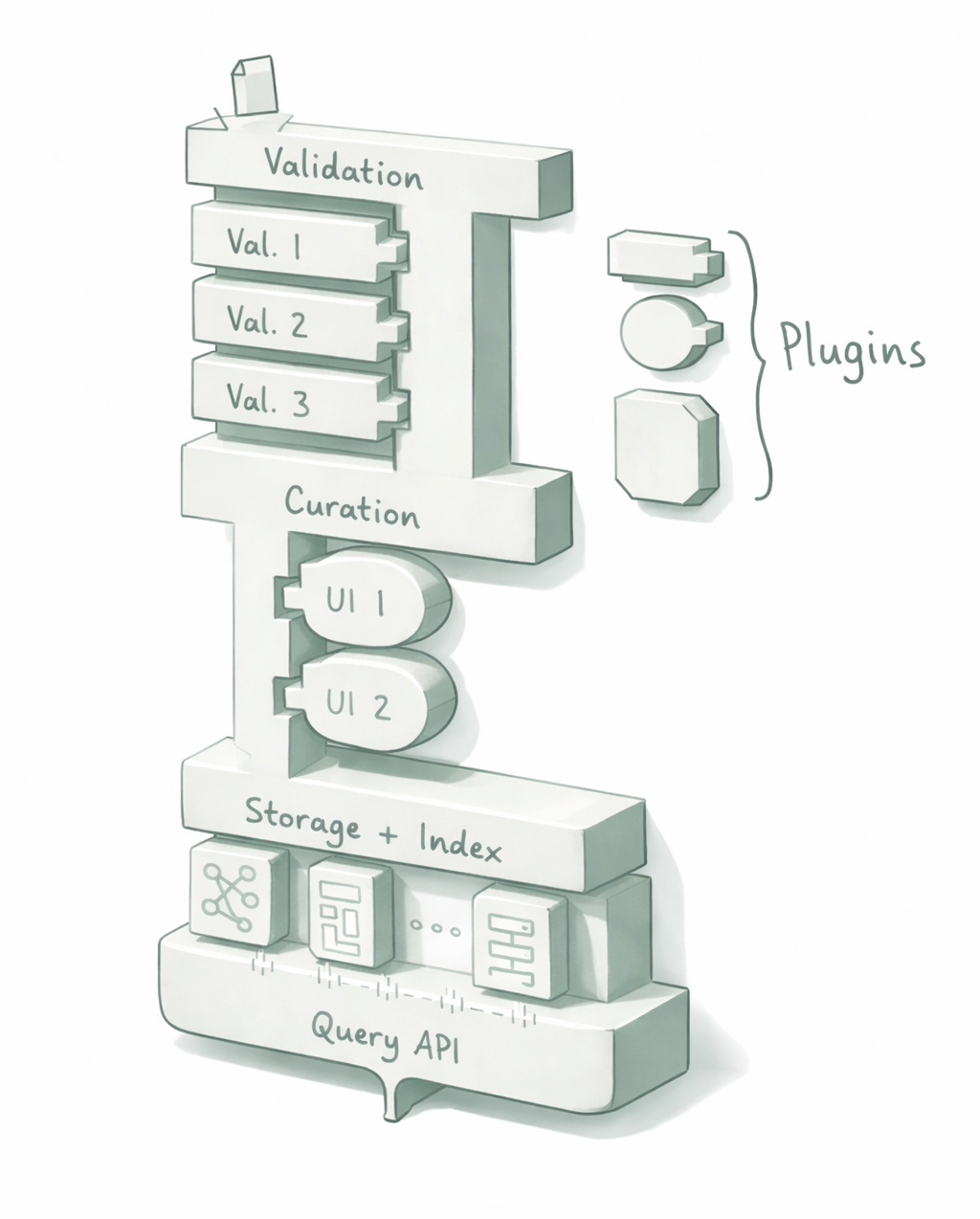
OSA is intentionally domain-agnostic: it doesn't assume your schema or what "good data" means.
You define the scientific rules:
OSA handles the archive machinery around it: lifecycle, versioning, and access.

OSA is licensed under Apache 2.0, so you can use it, extend it, and operate it with long-term control.
It's developed alongside the OSA Protocol, a community-governed specification for defining records, validation, and discovery across scientific archives.
The specification is drafted and open for feedback. A reference implementation is being built.
Want to contribute code? Pick up an issue